




1. LES UTILITAIRES EXPORT ET IMPORT▲
1-1. Introduction▲
Avant tout il faut préciser que cette méthode est une méthode logique de sauvegarde
(Export) et de restauration des données (Import). Elle va nous permettre de sauvegarder
le contenu logique d'une base de données dans un fichier de transfert Oracle au format
binaire, ou fichier dump. Ce fichier pourra donc être relu pour recréer des objets
qu'il contient. Ce transfert peut s'accomplir sur une même base ou même sur deux bases
Oracle, et cela même si leurs configurations matérielles et logicielles diffèrent.
Cela signifie que l'on peut tout à fait exporter une base sous Windows pour l'importer
sous Linux ou Unix (sauf pour les tablespaces transportables).
Ces deux utilitaires qui peuvent être alors employés comme des techniques de sauvegarde
peuvent être exécutés à partir de n'importe quel client NET*8 (le fichier DUMP est
traité, dans ce cas, de manière locale par rapport au client : lors d'un import ou
d'un export à partir d'un client NET*8, il faut faire attention car cette opération peut
augmenter le trafic du réseau et affecter ce dernier de manière importante. Autre précision
de taille : la version de l'utilitaire Import ne peut être antérieure à celle de l'utilitaire
Export, plus précisément on ne saurait exporter une base de données Oracle 9i pour l'importer
sur une base de données 8i avec leur utilitaire d'origine. Et enfin dernier détail mais non
des moindres, ne compressez jamais un fichier dump avec un outil de compression système Winzip
(Windows) ou GZIP (Linux - Unix), vous risqueriez d'avoir de mauvaises surprises lors de sa
décompression.
1-2. Les différents modes d'export et d'import▲
1-2-a. Niveau base de données complète▲
C'est le mode le plus complet, lors de ce type d'exportation tous les objets de la base sont exportés à l'exception de certains utilisateurs : SYS, ORDSYS, CTXSYS, MDSYS et ORDPLUGINS. Par contre les informations relatives aux structures de base de données, telles que les définitions de tablespaces et de segments de rollback, sont incluses. Lors de L'insertion des données tout ces objets sont importés et créés dans la base de destination : le paramètre FULL permet de spécifier ce mode pour l'exportation et l'importation.
1-2-b. Niveau utilisateur▲
Dans ce cas là, ce sont tous les objets appartenant à un utilisateur qui sont exportés: tables, fonctions, synonymes, déclencheurs, liens de bases de données… Le paramètre OWNER permet de désigner les utilisateurs que l'on désire exporter et le paramètre FROMUSER désigne quel est l'utilisateur à importer du fichier Dump (le paramètre TOUSER nous indique quand à lui le schéma destinataire).
1-2-c. Niveau table▲
Lors de l'exportation de tables individuelles tous leurs objets associés (index, contraintes, déclencheurs, privilèges …) sont écrits dans le fichier DUMP. Lors de l'importation tout comme l'exportation les tables doivent être nommées grâce au paramètre TABLES.
1-2-d. Niveau tablespace▲
Lors de l'exportation, des métas donnés concernant les tablespaces spécifiés et les objets qu'ils contiennent sont écrites dans un fichier DUMP.
1-2-e. Privilèges pré-requis▲
| Actions | Privilège ou rôle nécessaire |
|---|---|
| Exporter son propre schéma | CREATE SESSION |
| Exporter d'autres schémas | SYSDBA, EXP_FULL_DATABASE et DBA |
| Exporter la base entière ou tablespaces | EXP_FULL_DATABASE |
| Importer un objet du fichier DUMP | IMP_FULL_DATABASE |
1-3. Les principaux paramètres de contrôle▲
1-3-a. Paramètres d'export▲
| Paramètre | Description | Valeur par défaut |
|---|---|---|
| Userid | chaîne de connexion à la base de données | |
| Buffer | Taille du buffer de transfert | 4096 |
| Compress | Compression des extents en un seul | Y |
| Contraints | Export des contraintes | Y |
| File | Nom du fichier DUMP | expdat.dmp |
| Log | Nom du fichier de sortie du compte-rendu, pour voir les erreurs en particulier | |
| Full | Export de toute la base | N |
| Grants | Export des privilèges | Y |
| Help | Affiche la liste des paramètres supportés, aucun DUMP généré. | N |
| Indexes | Export des index | Y |
| Owner | Utilisateur(s) à exporter | userid |
| Parfile | Fichier contenant les paramètres d'export | |
| Recordlength | Taille des enregistrements (migration SE) | |
| Record | Indique que l'export doit stocker les informations sur les exports et les objets exportés | Y |
| Inctype | Export incrémental (COMPLETE, CUMULATIVE, INCREMENTAL) | |
| Rows | Export des lignes | |
| Query | Définit une condition de filtre pour exporter un sous-ensemble | |
| Tables | Table(s) à exporter | |
| Consistent | Positionne sa session en " READ ONLY " le temps de l'export. Cela permet donc de préserver la cohérence des données exportées. | N |
| Direct | Chargement direct par tableau | N |
| Statistics | Analyse des objets exportés | ESTIMATE |
| Feedback | Affiche la progression de l'export tous les n enregistrements | N |
| Point_in_time_Recover | Indique si on autorise l'export des tablespaces | N |
| Recover_Tablespaces | Liste des tablespaces à sauvegarder | |
| Volsize | Nombre d'octets à écrire sur chaque volume bande |
1-3-b. Paramètres d'import▲
| Paramètre | Description | Valeur par défaut |
|---|---|---|
| Userid | chaîne de connexion à la base de données | |
| Buffer | Taille du buffer de transfert | 10240 |
| Commit | Ecriture régulière des blocs de données | N |
| File | Nom du fichier DUMP | expdat.dmp |
| Log | Nom du fichier de sortie du compte-rendu, pour voir les erreurs en particulier | |
| Fromuser | Utilisateur à exporter vers TOUSER | |
| Full | Import de tout le contenu du DUMP | N |
| Grants | Export des privilèges | Y |
| Help | Affiche la liste des paramètres supportés, aucun DUMP généré. | N |
| Ignore | Ignore les erreurs et continue l'import | N |
| Indexes | Import des index | Y |
| Parfile | Fichier contenant les paramètres d'import | |
| Recordlength | Taille des enregistrements (migration SE) | |
| Rows | Import des données | Y |
| Destroy | Détruit les objets s'ils existent avant de les importer | N |
| Show | Liste le contenu du fichier d'export, aucune opération n'est effectuée dans la base. | N |
| Tables | Table(s) à importer | |
| Touser | Utilisateur destinataire | |
| Charset | Code alphabet du pays de référence s'il est différent de celui de la création de base | NLS_LANG |
| Point_in_time_recover | Indique si on autorise l'import des tablespaces | N |
| Skip_unusable_indexes | Permet de repousser la reconstruction de l'index après l'insertion des données dont ils dépendent | N |
| Analyze | Exécute la commande ANALYZE dans le fichier dump | Y |
| Feedback | Affiche la progression de l'import tous les n enregistrements | 0 |
| Volsize | Nombre d'octets dans le fichier pour chaque volume bande |
1-4. Deux façons d'exporter et d'importer▲
1-4-a. En ligne de commande▲
C:\> exp userid=system/manager file=c:\backup\export_full.dump
log=c:\control\export_full.log full=y rows=n
Ici, on se connecte à la base en tant que SYSTEM (userid=system/manager) et on exporte
toute la base (full=y) sans les données (rows=n). On sauvegarde la sortie dans le
fichier de log (log=c:\control\export_full.log).
Voici quelques exemples suplémentaires :
C:\> exp userid=system/manager file=c:\backup\export_full.dump
log=c:\control\export_full.log owner=scottC:\> exp userid=system/manager file=c:\backup\export_full.dump
log=c:\control\export_full.log tables=scott.accountC:\> exp userid=system/manager file=c:\backup\export_full.dump
log=c:\control\export_full.log tablespaces=userL'export de tablespace est implémenté depuis la version 8i d'Oracle et est connu sous la dénomination de tablespace transportable.
Les exemples suivants permettent d'importer les fichiers générés dans les exemples précédents.
C:\> imp userid=scott/tiger file=c:\backup\export_full.dump
log=c:\control\export_full.log owner=scottC:\> imp userid=system/manager file=c:\backup\export_full.dump
log=c:\control\export_full.log fromuser=scott touser=testl'utilisateur de connexion (indiqué dans userid) doit naturellement être autorisé à créer les objets dans le shéma TEST.
C:\> imp userid=system/manager file=c:\backup\export_full.dump
log=c:\control\export_full.log fromuser=scott touser=test tables=scott.accountC:\> imp userid=system/manager file=c:\backup\export_full.dump
log=c:\control\export_full.log1-4-b. En utilisant un fichier de paramètres▲
Nous avons pu voir dans les exemples précédents que la ligne de commande peut devenir
très fastidieuse à écrire. Afin de faciliter la maintenance des scripts, les utilitaires d'export et import
permettent d'indiquer un fichier de paramètres via l'option parfile.
Ainsi ce fichier est simplement l'énumération des paramètres à appliquer. Avec le fichier c:\backup\parfile.prm suivant :
userid=system/manager
file=c:\exp_scott.dmp
log=c:\exp_scott_log.txt
owner=scott
rows=n
Les commandes suivantes sont équivalentes :
exp userid=system/manager file=c:\exp_scott.dmp log=c:\exp_scott_log.txt
owner=scott rows=n
- OU -
exp parfile=c:\backup\parfile.prmimp userid=system/manager file=c:\exp_scott.dmp log=c:\exp_scott_log.txt
owner=scott rows=n
- OU -
imp parfile=c:\backup\parfile.prm1-5. Exporter selon une condition▲
Depuis la version 8i , il est possible de n'exporter qu'une partie de la table et non pas la totalité.
Il suffit de le préciser par l'option QUERY. Dans cette exemple nous allons exporter les personnes dont le salaire est supérieur à 500, dropper la table et enfin la réimporter.
SQL> select * from dvp_loader ;
NOM SALAIRE
-------------------- ----------
Jaouad 100
orafrance 200
léoanderson 300
bouyao 400
Nuke_y 500
sheikyerbouti 600
pomalaix 700
titides 800
aline 900
denisys 1000
niourk 1100On souhaite donc avoir un fichier qui contient les données correspondant à la requête suivante :
SQL> select * from dvp_loader where salaire > 500;
NOM SALAIRE
-------------------- ----------
sheikyerbouti 600
pomalaix 700
titides 800
aline 900
denisys 1000
niourk 1100
6 ligne(s) sélectionnée(s).La commande d'export sera alors la suivante :
$ exp system/XXXXX file=/ora/admin/dba/log/exp_query.dmp tables=formation.dvp_loader query="'where salaire > 500'"
Export: Release 8.1.7.4.0 - Production on Mon Sep 26 16:18:37 2005
(c) Copyright 2000 Oracle Corporation. All rights reserved.
Connected to: Oracle8i Enterprise Edition Release 8.1.7.4.0 - 64bit Production
With the Partitioning option
JServer Release 8.1.7.4.0 - 64bit Production
Export done in WE8ISO8859P15 character set and WE8ISO8859P15 NCHAR character set
About to export specified tables via Conventional Path ...
Current user changed to FORMATION
. . exporting table DVP_LOADER 6 rows exported
Export terminated successfully without warnings.Il y a bien 6 lignes exportées. Vérifions que les données sont bien les bonnes.
$ imp system/sinadmin file=/ora/admin/dba/log/exp_query.dmp fromuser=formation touser=formation tables=dvp_loader log=log.imp
Import: Release 8.1.7.4.0 - Production on Mon Sep 26 16:42:22 2005
(c) Copyright 2000 Oracle Corporation. All rights reserved.
Connected to: Oracle8i Enterprise Edition Release 8.1.7.4.0 - 64bit Production
With the Partitioning option
JServer Release 8.1.7.4.0 - 64bit Production
Export file created by EXPORT:V08.01.07 via conventional path
import done in WE8ISO8859P15 character set and WE8ISO8859P15 NCHAR character set
. importing FORMATION's objects into FORMATION
. . importing table "DVP_LOADER" 6 rows imported
Import terminated successfully without warnings.SQL> select * from dvp_loader;
NOM SALAIRE
-------------------- ----------
sheikyerbouti 600
pomalaix 700
titides 800
aline 900
denisys 1000
niourk 1100
6 ligne(s) sélectionnée(s).Voila une option très utile pour rafraichir un jeu de test par exemple.
2. SAUVEGARDE A FROID▲
2-1. Introduction▲
Une sauvegarde à froid signifie qu'un arrêt de la base de données est effectué. Lorsque la base est arrêtée, l'activité
est interrompue et les fichiers peuvent alors être copiés sans corruption de données.
Nous allons donc vous fournir un exemple de script pour automatiser le processus et vous expliquer comment
restaurer les données modifiées entre la dernière sauvegarde à froid et un instant choisi.
2-2. Sauvegarde▲
Le script suivant permet de sauver les fichiers de la base de données sous Windows.
Il génère le script de sauvegarde des fichiers (datafiles, logfiles, controlfile et tempfile) qui copie ces fichiers
dans le répertoire défini par la variable repertoire.
Il devra être adapté selon vos chemins personnels et surtout l'OS (copy sera remplacé par cp pour Unix par exemple).
-- Variables d'environnement de SQL*Plus de formatage de l'affichage
Set feedback off
Set Linesize 200
Set Heading off
Set Pagesize 0
Set Trimspool off
Set Verify off
define repertoire ='c:\archive' -- répertoire de destination des fichiers sauvegardés
define fichier_control=c:\control_backup.sql -- définition du fichier de sortie
spool &fichier_control
select 'host copy ' || name || ' &repertoire ' from v$datafile order by 1 ;
select 'host copy ' || member || ' &repertoire ' from v$logfile order by 1 ;
select 'host copy ' || name || ' &repertoire ' from v$controlfile order by 1 ;
select 'host copy ' || name || ' &repertoire ' from v$tempfile order by 1 ;
spool off
-- Fermeture de la base de données pour avoir des fichiers synchronisés
shutdown immediate
@&fichier_control
startup3. SAUVEGARDE A CHAUD▲
3-1. Introduction▲
Comme nous venons de le voir, effectuer une restauration ou récupération d'une base de données implique
que la base soit arrêtée, cependant dans des environnements à haute disponibilité cela est parfois impossible. Une
solution dans ce cas existe: "Hot backup" ou sauvegarde à chaud. Le problème est le suivant, dans le cas d'une haute disponibilité,
forcément l'état des fichiers change constamment : des modifications sont apportés dans les fichiers de données, des informations
de contrôle sont écrites dans les fichiers de contrôle, et des informations de reprise sont consignées dans les fichiers REDO,
lesquels peuvent également être archivés. Pour effectuer une sauvegarde dans ce cas, la solution est de placer chaque tablespace
dans le mode de sauvegarde et de sauvegarder les fichiers de données, puis de rétablir le tablespace dans le mode normal.
On sauvegarde donc des fichiers incohérents puisque les SCN, contenus dans les entêtes de fichiers de données sont différents. Il
faudra effectuer une récupération de support pour rendre ces différents SCN cohérents et pouvoir ouvrir la base.
Etant donné que les changements qui ont lieu durant la phase de sauvegarde d'un tablespace donnent lieu à une consignation dans le
flux de reprise, la base doit être en mode ARCHIVELOG.
Les tablespaces en mode lecture seule (" alter tablespace tools read only ") ne peuvent pas être sauvegardé car la base ne peut pas
les modifier, pas plus que ceux gérés localement. Dans ce cas là, la solution consiste à les recréer.
3-2. Sauvegarde▲
Tout d'abord nous allons commencer par créer un script de sauvegarde à chaud de la base de données. Ce script que nous appellerons sauvegarde_chaud.sql nous aidera dans le traitement des tablespaces et des fichiers de données.
SET feedback off pagesize 0 heading off verify off linesize 100 trimspool on
PROMPT veuillez entrer le chemin du répertoire destinataire des sauvegardes
ACCEPT repertoire
PROMPT veuillez entrer le chemin du premier fichier
ACCEPT fichier
PROMPT veuillez entrer le chemin du second fichier
ACCEPT spool
SPOOL &fichier
PROMPT spool &spool ;;
PROMPT archive log list ;;
PROMPT alter system switch logfile ;;
SELECT ' alter tablespace ' || tablespace_name || ' begin backup ; '
FROM dba_tablespaces
WHERE status NOT IN ('READ ONLY', 'INVALID', 'OFFLINE');
SELECT ' host copy ' || file_name || ' &repertoire '
FROM dba_data_files
WHERE tablespace_name NOT IN (
SELECT tablespace_name
FROM dba_tablespaces
WHERE status IN
('READ ONLY', 'INVALID', 'OFFLINE'));
SELECT ' alter tablespace ' || tablespace_name || ' end backup ; '
FROM dba_tablespaces
WHERE status NOT IN ('READ ONLY', 'INVALID', 'OFFLINE');
PROMPT alter database backup controlfile to '&repertoire\control.ctl' REUSE ;;
PROMPT alter system switch logfile ;;
PROMPT archive log list ;;
PROMPT spool off ;;
SPOOL off;
@&fichier
Attention, il convient d'adapter ce script à vos besoins, particulièrement selon l'OS : ici c'est un script destiné à Windows.
Oracle propose également des scripts dans Metalink
Le script précédant doit générer et exécuter un autre script de la forme :
spool c:\oracle\sauvegarde\hot_backup.sql ;
archive log list ;
alter system switch logfile ;
alter tablespace SYSTEM begin backup ;
alter tablespace RBS begin backup ;
alter tablespace USERS begin backup ;
alter tablespace TEMP begin backup ;
alter tablespace TOOLS begin backup ;
alter tablespace INDX begin backup ;
alter tablespace DRSYS begin backup ;
host copy C:\ORACLE\ORADATA\BD0\USERS01.DBF c:\oracle\sauvegarde
host copy C:\ORACLE\ORADATA\BD0\DR01.DBF c:\oracle\sauvegarde
host copy C:\ORACLE\ORADATA\BD0\TOOLS01.DBF c:\oracle\sauvegarde
host copy C:\ORACLE\ORADATA\BD0\INDX01.DBF c:\oracle\sauvegarde
host copy C:\ORACLE\ORADATA\BD0\RBS01.DBF c:\oracle\sauvegarde
host copy C:\ORACLE\ORADATA\BD0\TEMP01.DBF c:\oracle\sauvegarde
host copy C:\ORACLE\ORADATA\BD0\SYSTEM01.DBF c:\oracle\sauvegarde
alter tablespace SYSTEM end backup ;
alter tablespace RBS end backup ;
alter tablespace USERS end backup ;
alter tablespace TEMP end backup ;
alter tablespace TOOLS end backup ;
alter tablespace INDX end backup ;
alter tablespace DRSYS end backup ;
alter database backup controlfile to 'c:\oracle\sauvegarde\control.ctl' REUSE ;
alter system switch logfile ;
archive log list ;
spool off ;
lorsque le tablespace est en mode sauvegarde, si une modification intervient sur un objet de celui-ci,
des reprises seront créées, ce qui surchargera la phase de récupération lorsque le tablespace sera à nouveau
placé dans le mode normal : donc veillez à effectuer cette opération lorsque le serveur est le moins sollicité.
Lorsqu'on positionne le mode sauvegarde, on peut alors copier le fichier de données, on peut effectuer cette
copie sans au préalable avoir placé le tablespace dans ce mode, cependant la sauvegarde qu'on obtiendra sera inutilisable.
Pour vérifier que le mode sauvegarde est bien activé, vérifiez le fichier des alertes (l'altération d'un tablespace y est consignée)
ou consultez la vue v$backup :
SELECT b.tablespace_name ,
b.file#,
b.status,
b.change# SCN,
b.time horodate
FROM v$backup b
ORDER BY tablespace_name;
TABLESPACE_NAME FILE# STATUS CHANGE# TIME
------------------- ------- ---------- ------------------ ---------- --------
DRSYS 7 NOT ACTIVE 524024 05/11/03
INDX 6 NOT ACTIVE 524023 05/11/03
RBS 2 NOT ACTIVE 524019 05/11/03
SYSTEM 1 NOT ACTIVE 524018 05/11/03
TEMP 4 NOT ACTIVE 524021 05/11/03
TOOLS 5 ACTIVE 1085795 20/11/03
USERS 3 NOT ACTIVE 524020 05/11/03Cette vue nous apprend, que le fichier 5 du tablespace TOOLS est en phase de récupération, et qu'il a été mis dans cet état le 20/11/03.
4. RESTAURATION DES DONNEES▲
4-1. Restauration des fichiers de données▲
La restauration de la base de données est particulièrement simple, elle est réalisée par les étapes suivantes :
- Arrêt de la base de données
- Suppression des datafiles, logfiles, controlfiles et tempfiles
- Restauration des fichiers
- Démarrage de la base de données
Si la sauvegarde à froid s'est bien déroulée alors le démarrage suite à la restauration des fichiers ne doit poser aucun problème.
Ici, on rétablit la base de données dans l'état dans lequel elle était lors de la dernière sauvegarde. Toutes les modifications de données entre l'heure de la sauvegarde et l'heure de la restauration seront perdues.
4-2. Restauration totale de la base de données▲
Restaurer la base de données à l'instant de la sauvegarde peut être salutaire mais c'est souvent insuffisant,
la perte des données devant être la plus petite possible.
Afin de récupérer le maximum de données il convient
donc de passer la base de données en mode ARCHIVELOG.
4-2-a. Définition du mode ARCHIVELOG▲
Lorsque des opérations sont exécutées dans la base, des entrées de reprise décrivant les modifications
apportées aux données sont consignées dans les fichiers REDO après être passées par le tampon REDO. Chaque base
doit au moins contenir deux fichiers REDO en ligne (généralement elle en compte trois).La raison principale est
que lorsqu'un fichier REDO est plein la base doit pouvoir continuer de consigner les descriptions des changements
qui interviennent. Pour empêcher d'écraser immédiatement les entrées du fichier en cours, la base poursuit la
consignation des modifications dans l'autre fichier. Cette phase s'appelle une commutation de journal (LOG SWITCH).
Vous pouvez demander à Oracle de consigner ces fichiers et donc éviter lors de la fin d'un cycle qu'ils ne soient
écrasés. Oracle les copie donc vers un ou plusieurs emplacements hors ligne... Cette procédure s'appelle l'archivage
du journal de reprise (assurée par le processus ARCH). Elle permet de produire un jeu de fichiers REDO archivés. Cette
option doit être activée et paramétrée pour pouvoir récupérer toutes les modifications.
Vous trouverez des compléments d'information sur cette page : Les redo logs.
4-2-b. Activation du mode ARCHIVELOG▲
Tout d'abord vérifiez que la base n'est pas déjà en mode ARCHIVELOG.
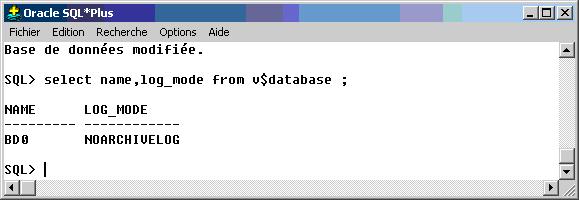
La vue v$database contient d'autres informations intéressantes que je vous invite à consulter.
Si la base n'est pas en mode ARCHIVELOG alors il faut modifier le fichier d'initiatisation de la base (init<SID>.ora), et ajouter ou modifier les paramètres suivantes :
# Uncommenting the line below will cause automatic archiving if archiving has
# been enabled using ALTER DATABASE ARCHIVELOG
# Permission d'utiliser le mode ARCHIVELOG
log_archive_start = TRUE
# Destination des archives de REDO
log_archive_dest_1 = "location=c:\oracle\oradata\BD0\archive"
log_archive_dest_2 = "location=c:\temp"
# Format de fichier des archives
log_archive_format = %%ORACLE_SID%%T%TS%S.ARCIl est possible de dupliquer les fichiers d'archives dans 5 (pour la 8i) ou 10 (depuis la 9i) répertoires destinations différents via le paramétre log_archive_dest_<n> (2 fichiers dans notre exemple). Cette option peut être utile pour sauver une archive dans une destination et garder une copie disponible plus facilement dans une autre destination par exemple.
Désormais, le paramétrage de la base est suffisant pour accepter le passage en mode ARCHIVELOG. Il convient donc de monter la base, positionner le mode ARCHIVELOG et ouvrir la base. C'est ce qu'illustre la figure suivante :
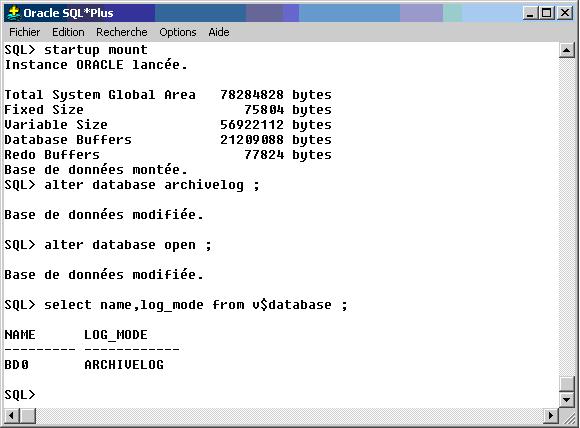
La commande alter database open peut ne pas s'exécuter si vous êtes sous Oracle 9i, pour ce faire, arrêtez de nouveau la base (shutdown immediate) puis redémarrez grâce à la commande : STARTUP
La base de données est bien en mode ARCHIVELOG, ainsi les redo logs seront archivés
à chaque switch assurant une sécurisation optimale de la base de données. Je vous rappelle que ces archives ne peuvent être utilisées que sur la base de données sauvegardée,
il convient donc de faire une sauvegarde complète (à froid de préférence) au plus vite suite à cette manipulation.
Vous pouvez consulter l'état des paramètres relatifs à l'archivage avec la commande suivante :
SELECT name, value
FROM v$parameters
WHERE name like 'log_archive%';Pensez bien à supprimer les archivelogs après leur sauvegarde, sinon vous risquez fort de consommer beaucoup d'espace disque. Voila un exemple de script sous Windows pour ce faire :
Prompt veuillez definir un repertoire de destination
Accept &repertoire_archivage
Prompt veuillez definir un fichier de sortie
Accept &fichier
prompt archivelog next ;;
select ' copy ' || name || ' &repertoire_archivage ' from v$archived_log
where completion_time >= trunc (sysdate) -1 and completion_time < trunc(sysdate) ;4-2-c. Restauration compléte à partir de la sauvegarde à froid▲
Je vous propose un cas pratique pour illustrer le modus operandi de cette restauration. Imaginons la perte du datafile c:\oracle\oradata\BD0\users01.dbf. La perte d'un datafile provoque immédiatement l'erreur suivante et arrête la base de données :
ORA-01157: impossible d'identifier ou de verrouiller le fichier de données 3 -
voir le fichier de trace DBWR
ORA-01110: fichier de données 3 :'C:\ORACLE\ORADATA\BD0\USERS01.DBF'
Windows a l'avantage de bloquer la suppression d'un fichier accédé par un processus, limitant ainsi les risques
de suppression accidentelle des datafiles. Néanmoins, cette fonctionnalité ne nous met pas à l'abri d'une panne matérielle.
Pour le test, vous devrez donc arrêter la base avant de supprimer le datafile.
La première étape consiste alors à restaurer le fichier de notre dernière sauvegarde complète (la vue v$recover_files permet de
retrouver le(s) fichier(s) à restaurer). Une fois que le fichier est à nouveau disponible il faut le resynchroniser. C'est à dire qu'il
faut rejouer les redos jusqu'à ce que les données soient complètement restaurées et que le numéro SCN du tablespace corresponde au numéro
SCN des autres tablespaces de la base de données.
Ensuite on démarre la base en prenant soin de lancer un RECOVER :
SQL> STARTUP MOUNT;
SQL> RECOVER DATABASE
media recovery completed
SQL> ALTER DATABASE OPEN;Il est probable que le RECOVER demande d'indiquer une archive manquante. Dans ce cas, essayez d'indiquer les redologs courant.
4-2-d. Restauration partielle à partir de la sauvegarde à froid▲
La restauration peut aussi être réalisée partiellement: PITR, Point in time recovery. Cela permet de repositionner la base de données à un point donné défini par un numéro SCN ou une date et heure. Nous prendrons comme exemple, la suppression du tablespace INDX par erreur.
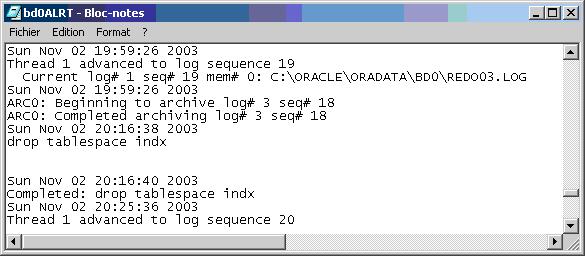
Dans ce fichier on peut voir que la suppression du tablespace a eu lieu le 02/11/2003 à 20:16:26 et que le dernier numéro de séquence est 19. Pour récupérer la situation la plus cohérente possible, nous allons restaurer jusqu'au numéro SCN de cette séquence.
SQL> SELECT sequence# as sequence,first_change# as SCN
FROM v$log_history
WHERE sequence#=19
SEQUENCE SCN
--------------------- ----------
19 383077Lançons maintenant la récupération (RECOVER DATABASE) en indiquant le SCN 383077 trouvé précédemment :
SQL> STARTUP MOUNT;
SQL> RECOVER DATABASE AUTOMATIC UNTIL SCN 383077;
SQL> ALTER DATABASE OPEN RESETLOGS;
L'option AUTOMATIC évite de devoir donner l'emplacement des archivelogs, et RESETLOGS réinitialise la séquence
de redologs à 1.
Lorsqu'on ouvre une base avec cette option, tous les fichiers de données et REDO archivés
reçoivent un nouveau SCN et une horodate de réinitialisation. Ce qui empêche de corrompre des fichiers de données
avec d'anciens fichiers archivés en s'assurant que les valeurs du SCN et de l'horodate de réinitialisation sont
cohérentes avec le fichier REDO. Cette commande peut prendre un certain temps avant de s'exécuter, car tout les
fichiers REDO en ligne sont reconstruits, chaque entête de fichiers de donnée est modifié, et les fichiers de contrôle
sont mis à jour. Une nouvelle sauvegarde cohérente est conseillé dans ce cas la.
Il est également possible de donner l'heure à laquelle on veut se positionner plutôt que le SCN.
Dans ce cas on exécutera :
SQL> STARTUP MOUNT;
SQL> RECOVER DATABASE AUTOMATIC UNTIL TIME '2003-11-02 20:16:20';
SQL> ALTER DATABASE OPEN RESETLOGS;Attention, vous constaterez que nous indiquons 20:16:20 soit 6 secondes avant le DROP. C'est simplement pour être certain de bien éviter le DROP.
Enfin, il est possible d'indiquer une récupération de toutes les archives jusqu'à ce que l'une d'elle soit introuvable. Les fichiers REDO sont donc appliqués un par un jusqu'à atteindre le fichier sur lequel on désire s'arrêter. Dans l'exemple suivant on utilise les fichiers de contrôle.
SQL> STARTUP MOUNT;
SQL> RECOVER DATABASE AUTOMATIC UNTIL CANCEL USING BACKUP CONTROL FILE;
SQL> ALTER DATABASE OPEN RESETLOGS;Cette récupération peut s'avérer nécessaire lorsqu'un fichier REDO est manquant. En effet Oracle détermine dans les fichiers archivés et en ligne les fichiers nécessaires et s'arrête lorsqu'il ne trouve pas le suivant (pensez que le redo courant n'est pas pris en compte, il faut donc bien l'indiquer). Ici nous allons interagir avec la procédure de restauration, en effet à la fin de chaque fichier REDO appliqué, la procédure nous demande de continuer ou d'arrêter.
Tapez set logsource "c:\archive" sous SQL*Plus pour modifier l'emplacement des archivelogs dans la session.
Ici la base est redémarrée est le fichier des alertes doit confirmer la récupération en indiquant par exemple :
Mon Nov 03 12:20:35 2003
RESETLOGS after complete recovery trought change 383077La commande RECOVER offre d'autres possibilités dont voici quelques exemples :
-- Récupération un fichier spécifique désigné par son nom
SQL > recover datafile 'c:\oracle\oradata\bd0\user01.dbf' ;
-- Récupération un fichier spécifique désigné par son identifiant
SQL > recover from 'e:\archived_log' datafile 5 ;
-- Récupération du tablespace USERS
SQL > recover from 'e:\archived_log' tablespace USERS ;
-- Récupération de plusieurs fichiers désignés par leur nom
SQL > recover from 'e:\archived_log'
datafile 'c:\oracle\oradata\bd0\user01.dbf',
'c:\oracle\oradata\bd0\user02.dbf' ;5. DUPLICATION D'UNE BASE DE DONNEES▲
5-1. Introduction▲
Il existe différents moyens de dupliquer une base données, soit en passant par une sauvegarde logique de la base de données qu'on importe sur la base clone
(Utilitaires EXPORT /IMPORT). Une autre méthode consiste à utiliser RMAN
(Recovery Manager), et enfin dernière solution que nous étudierons durant ce chapitre qui est une copie à partir d'une sauvegarde incohérente (hot backup).
Cette méthode permet donc de créer une copie exacte de la base de données, que vous pourrez utiliser pour tester si vos sauvegardes sont correctes et si une
restauration à partir de cette sauvegarde fonctionne correctement. Avant de commencer n'oubliez pas que si vous êtes sous Windows, il existe une étape de plus
par rapport à Linux ou Unix qui consiste en la création du service de l'instance.
Ici, nous copierons bd0 dans bd1, sur le même serveur Windows.
Afin de réduire le risque de difficulté il convient de prendre quelques précautions :
- La version majeure (jusqu'au 3° digit, par exemple 9.2.0) d'Oracle installée doit être identique sur chacun des systèmes : source et cible
- Les OS installés doivent également être de la même version
- Si vous transférez les fichiers via FTP, pensez bien à faire un transfert de type binaire
- La suite sera plus simple si sur le serveur cible vous configurez une connexion vers la base source
- La recréation du fichier de contôle n'est pas nécessaire lors d'un clone : même nom d'instance, même arborescence
5-2. Préparation à la création d'une base de données clone▲
SET oracle_sid=bd1
oracle_base=c:\oracle
oracle_home=c:\oracle\product\9.2.0
oracle_data=c:\oradata\%oracle_sid%
oracle_admin=%oracle_base%\admin\%oracle_sid%
mkdir %oracle_admin%
mkdir %oracle_admin%\pfile
mkdir %oracle_admin%\bdump
mkdir %oracle_admin%\cdump
mkdir %oracle_admin%\udump
mkdir %oracle_admin%\create
mkdir %oracle_data%
mkdir %oracle_data%\archive5-3. Fichier d'initialisation▲
Copiez le fichier de BD0 dans BD1.
copy %oracle_base%\admin\bd0\pfile\initbd0.ora %oracle_admin%\pfile\initbd1.ora
notepad %oracle_home%\dbs\bd1.oraDans %oracle_home%\dbs\bd1.ora (qui s'ouvre dans notepad) ajoutez ou modifiez le paramètre ifile :
ifile=c:\oracle\admin\bd1\pfile\initbd1.oraEnfin, modifiez le fichier c:\oracle\admin\bd1\pfile\initbd1.ora pour remplacer les références à bd0 et son arborescence.
5-4. Fichier de mots de passe▲
Bien que cela ne soit pas une étape primordiale à la création d'une base de données, il est fortement conseillé de créer ce fichier, dans un souci de sécurisation de la base de données.
orapwd file=$oracle_home/dbs/orapwbd1 password=bd0 entries=4File définit le chemin et le nom du fichier de mots de passe.
Password est le mot de passe pour les comptes SYS et INTERNAL.
Entries est le nombre maximum de comptes ayant le privilège OPER et DBA.
5-5. Création de services sous Windows▲
Cette étape est nécessaire sous Windows, par la suite vous pouvez aller configurer directement, dans la base de registre ou par le biais d'ORADIM, le démarrage automatique ou pas de l'instance lors du démarrage du serveur.
oradim -NEW -SID BD0 -intpwd BD0Notez que dans le fichier des mots de passe comme ici, le mot de passe indiqué est bien bd0, le mot de passe de SYS de la base source.
5-6. Sauvegarde de la base de donnée source▲
Je vous renvoie au paragraphe des sauvegardes pour cette étape : Sauvegarde qui décrit le process à appliquer pour faire une sauvegarde complète de la base.
5-7. Préparer le script de création du fichier de contrôle▲
Au lieu de saisir manuellement toutes les commandes nécessaires pour la création des différents fichiers de contrôle de la base, nous allons contourner le problème grâce à la commande suivante :
SQL> alter database backup controlefile to trace;
Cette commande permet de générer un script de création des controlfiles, ce script permet alors de modifier les chemins des datafiles et redos de l'instance cible.
Il est généré dans le répertoire des traces utilisateurs indiqué par le paramètre user_dump_dest de la base source.
Recherchez le dernier fichier trace généré (ce devrait être le résultat de la commande précédente) et copiez-le dans le répertoire
c:\oracle\admin\bd1\create.
Ce script contient des informations non pertinentes pour notre besoin, il convient donc de l'adapter : épurez-le en ne gardant que le code de la section resetlogs,
adaptez les chemins de fichier à la nouvelle structure, ajoutez l'option PFILE au démarrage et modifiez REUSE "BD0" par SET "BD1" pour renommer la base.
Vous devriez obtenir un fichier similaire au suivant :
STARTUP NOMOUNT PFILE="c:\oracle\admin\bd1\pfile\initbd1.ora"
CREATE CONTROLFILE set DATABASE "BD1" RESETLOGS ARCHIVELOG
MAXLOGFILES 32
MAXLOGMEMBERS 2
MAXDATAFILES 32
MAXINSTANCES 16
MAXLOGHISTORY 1815
LOGFILE
GROUP 1 'C:\ORACLE\ORADATA\BD1\REDO03.LOG' SIZE 1M,
GROUP 2 'C:\ORACLE\ORADATA\BD1\REDO02.LOG' SIZE 1M,
GROUP 3 'C:\ORACLE\ORADATA\BD1\REDO01.LOG' SIZE 1M
DATAFILE
'C:\ORACLE\ORADATA\BD1\SYSTEM01.DBF',
'C:\ORACLE\ORADATA\BD1\RBS01.DBF',
'C:\ORACLE\ORADATA\BD1\USERS01.DBF',
'C:\ORACLE\ORADATA\BD1\TEMP01.DBF',
'C:\ORACLE\ORADATA\BD1\TOOLS01.DBF',
'C:\ORACLE\ORADATA\BD1\INDX01.DBF',
'C:\ORACLE\ORADATA\BD1\DR01.DBF'
CHARACTER SET WE8ISO8859P1
;Enfin, exécutez le script ainsi obtenu.
5-8. Récupération de la base de données▲
A moins d'avoir restauré une sauvegarde à froid, il est nécessaire de rejouer les redos comme vu au paragraphe 4.2.c.
Commençons par indiquer le chemin des archivelogs de la base bd0 avant de lancer la récupération proprement dite :
SQL> set logsource c:\archive
SQL> RECOVER DATABASE USING BACKUP CONTROLFILE;Pensez que si un fichier n'est pas trouvé c'est probablement que c'est le redolog courant qu'Oracle demande.
5-9. Démarrage de la base de données▲
Nous arrivons à l'objectif fixé, il ne reste plus qu'à ouvrir la base de données.
SQL> alter database open resetlogs;Vous trouverez un autre article traitant de ce théme à cette adresse : Copie de la base de données.
6. BASE DE SECOURS : STANDBY DATABASE▲
6-1. Introduction▲
Si comme nous le supposions au chapitre 3, vous êtes dans un système à haute disponibilité voir même à très haute disponibilité,
la moindre indisponibilité même courte de la base de données peut s'avérer être incompatible avec l'activité de l'entreprise (imaginez donc une indisponibilité
de Developpez.com ;-)).
Si votre structure ne peut se permettre un temps d'attente trop élevé, vous devez donc trouver un moyen de disposer rapidement d'une autre base de production opérationnelle.
Oracle a tout prévu, cela consiste en la création d'une base de données de secours (ou Standby Database in English). Cette solution inclut deux bases de données. La première qui est la base de données
principale (dite également primaire ou source), c'est la base active. La seconde est la base de secours, il s'agit d'une copie de la base principale. La base de secours a
généralement le même nom d'instance et le même nom de base de données (sauf si elle est sur le même hôte que la base principale : déconseillé puisque ne couvre pas la panne du serveur).
Cette solution existe depuis la version 7.3 d'Oracle, puis avec la version 8.0, une nouvelle solution à été introduite avec l'utilitaire RMAN.
Le processus de fonctionnement se déroule en 3 étapes principales :
- Création d'une copie de la base de production
- Synchronisation des données via les fichiers archivelogs de la base principale
- Activation de la base de secours à la demande
Attention, ce sont bien les archivelogs qui sont rejoués sur la base de secours. Cela signifie qu'elle aura toujours un redolog de retard : le redolog courant. Il convient donc d'adopter une solution applicative pour assumer ce décalage dans les données qui peut poser des problèmes fonctionnels importants.
- La version majeure (jusqu'au 3° digit, par exemple 9.2.0) d'Oracle installée doit être identique sur chacun des systèmes : source et cible
- Les OS installés doivent également être de la même version
- La base de données principale doit être en mode ARCHIVELOG
- La synchronisation de la base de secours se fait via NET*8
- Evitez d'installer la base de secours sur le même serveur que la base principale pour couvrir les risques de panne matérielle
6-2. Création d'une base de secours▲
Reprenons le script du chapitre précédent pour créer l'arborescence :
SET oracle_sid=bd1
oracle_base=c:\oracle
oracle_home=c:\oracle\product\9.2.0
oracle_data=c:\oradata\%oracle_sid%
oracle_admin=%oracle_base%\admin\%oracle_sid%
mkdir %oracle_admin%
mkdir %oracle_admin%\pfile
mkdir %oracle_admin%\bdump
mkdir %oracle_admin%\cdump
mkdir %oracle_admin%\udump
mkdir %oracle_admin%\create
mkdir %oracle_data%
mkdir %oracle_data%\archiveSous Linux/Unix il est possible de créer des liens vers le fichier des mots de passe et les fichiers de configuration NET*8 (tnsnames.ora, sqlnet.ora, listener.ora). Sinon, une copie de fichier est nécessaire, pensez alors bien à modifier ces fichiers lorsqu'ils sont modifiés pour la base principale.
6-3. Sauvegarde à chaud de la base de secours▲
Je vous renvoie au paragraphe des sauvegardes pour cette étape : Sauvegarde qui décrit le process à appliquer pour faire une sauvegarde complète de la base.
6-4. Configurer le fichier de paramètre de la base de secours▲
Voila un exemple fichier d'initialisation spécifique pour la base de secours :
# Même nom de base de données que la base principale
DB_name = BD0
# Nom de l'instance de la base de secours, il peut être différent
# pour faciliter son identification
Instance_name = BD1
# Nom de service utilisé pour la copie des archivelogs
Services_name=BD1
# Chemin des controlfiles de la base de secours
control_files = ("c:\oracle\oradata\BD1\control01.ctl",
"c:\oracle\oradata\BD1\control02.ctl",
"c:\oracle\oradata\BD1\control03.ctl")
log_archive_dest_1 = "location=E:\oracle\oradata\BD1\archive"
# Chemin des archivelogs à appliquer
standby_archive_dest = "location=E:\oracle\oradata\BD1\archive"
background_dump_dest = E:\oracle\admin\BD1\bdump
user_dump_dest = E:\oracle\admin\BD1\udump
# Donne la règle de conversion des chemins des datafiles dans le fichier
# de contrôle
db_file_name_convert = "C:\oracle\oradata\BD0, E:\oracle\oradata\BD1"
# Donne la règle de conversion des chemins des logs
log_file_name_convert = "C:\oracle\oradata\BD0, E:\oracle\oradata\BD1"
# Permet de faire coexister deux bases de données sur une même machine
lock_name_space = BD16-5. Monter la base de secours▲
C:\set oracle_sid=bd0
C:\sqlplus "/ as sysdba"
SQL > Startup nomout ;
SQL > alter database mount standby database ;6-6. Récupération automatique▲
Lorsque la récupération automatique est activée, on commence par la configuration de NET*8 pour que le processus ARCH de la base principale communique avec le processus RFS de la base de secours. Il faut ensuite placer la base dans le mode de récupération. Cela a pour conséquence de copier et d'appliquer dynamiquement les fichiers REDO archivés. Il faut donc configurer le processus ARCH de la base principale pour lui indiquer d'archiver les fichiers REDO vers un service NET*8 en plus du répertoire local.
6-6-a. Configuration des services NET*8▲
Soit grâce à l'utilitaire NET*8 soit par action directe sur les fichiers : listener.ora, sqlnet.ora et tnsnames.ora, vous devez créer un service pour la base de base de données nommé BD1.
Pour le listener, utilisez le protocole IPC si votre base de secours est sur le même hôte que la base principale.
Les fichiers listener.ora, sqlnet.ora et tnsnames.ora se trouvent généralement dans le répertoire suivant : %oracle_home%/network/admin.
Lorsqu'on crée un nouveau service de base de données, en utilisant le protocole IPC pour le listener, ainsi qu'un nouveau nom de service TNS associé, le but est évidemment de permettre à
la base principale BD0 de se connecter via le listener à la base de secours.
Une connexion est donc établie chaque fois qu'un fichier REDO archivé devra être copié depuis la base principale vers celle de secours. Le listener doit être redémarré pour que ces changements soient pris en compte
(via la commande Shell lsnrctl reload).
Le fichier tnsnames.ora de la base de secours doit utiliser le protocole IPC car elle est locale, par contre le fichier de la base principale doit utiliser le protocole TCP, car les archivelogs sont transmis via le réseau.
6-6-b. Mode de récupération▲
Nous pouvons donc passer à la configuration de la base de secours. Plus précisément il faut configurer la base dans le mode "Récupération".
Pour cela connectez-vous à la base en tant que SYS puis saisissez la commande suivante :
SQL> RECOVER MANAGED STANDBY DATABASE;Dans ce cas là, le processus d'arrière plan RFS de la base de secours reçoit les archives transmises par la base principale, RFS met également le fichier de contrôle à jour avec les nouvelles informations d'archivage. Le fichier est appliqué dès que ce dernier est disponible dans la destination d'archivage. Ce mécanisme de récupération vérifie la présence de tout nouveau fichier REDO toutes les 15 secondes et ne prend fin qu'à l'émission de la commande suivante :
SQL> RECOVER MANAGED STANDBY DATABASE CANCEL;
La configuration de la base principale à pour but essentiel de lui indiquer d'envoyer les fichiers archivelogs au nouveau service. Pour cela vous devez ajouter une seconde
destination d'archivage dans le fichier de paramètre : log_archive_dest_3="mandatory services=BD1 reopen=30"
Ce paramètre peut être modifié dynamiquement via alter system.
Le mot clé mandatory signifie que les fichiers archivelogs doivent être transférés avec succès avant de pouvoir être réutilisé en ligne. Le mot clé reopen définit le délai requis en seconde avant de procéder à
une nouvelle tentative de transfert si une erreur est retournée au processus ARCH.
Il existe également des commandes dynamiques permettant de désactiver ou d'activer la transmission des fichiers REDO :
SQL> alter system set log_archive_state_3=DEFER; -- désactivation
SQL> alter system set log_archive_state_3=ENABLE; -- réactivation6-6-c. Configuration de la base principale▲
Mettre fin à la phase de récupération :
SQL > RECOVER MANAGED STANDBY DATABASE CANCEL;Ouvrir la base de données BD1 en lecture seul :
SQL > alter database open read only;Pour rebasculer dans le mode de récupération :
SQL > SHUTDOWN IMMEDIATE ;
SQL > STARTUP NOMOUNT ;
SQL > ALTER DATABASE MOUNT STANDBY DATABASE ;
SQL > RECOVER MANAGED STANDBY DATABASE ;Cette phase est importante car elle permet que l'archivage fonctionne et que les changements opérés sur la base principale soient logiquement répercutés sur la base de secours. Si une base de secours est activée, elle ne pourra revenir dans son état précédent.
6-7. Activer la base de secours▲
SQL > RECOVER MANAGED STANDBY DATABASE CANCEL;SQL > alter database open read only;SQL > SHUTDOWN IMMEDIATE ;
SQL > STARTUP NOMOUNT ;
SQL > ALTER DATABASE MOUNT STANDBY DATABASE ;
SQL > RECOVER MANAGED STANDBY DATABASE ;Cette phase est importante car elle permet à l'archivage de fonctionner et d'appliquer les changements de la base principale sur la base de secours. Si une base de secours est activée, elle ne pourra revenir dans son état précédent.
SQL > ALTER DATABASE ACTIVATE STANDBY DATABASE;
SQL > SHUTDOWN IMMEDIATE;
SQL > STARTUP;7. UTILISATION DU LOGMINER▲
7-1. Introduction▲
Puisque nous parlons de récupération incomplète ou limitée dans le temps, le logminer peut être une bonne
solution pour déterminer ce point d'arrêt dans le temps. C'est également un moyen de lire les fichiers archivelogs et en ligne,
mais surtout de défaire ou de refaire des instructions. Le logminer se compose d'un jeu de vues du dictionnaire
et de quelques procédures stockées. Plus précisément, Oracle affecte à chaque table un numéro d'objet et à chacune de ses colonnes un identifiant qui signale le type d'objet (date, varchar, number …) grâce à l'emploi du fichier de dictionnaire Oracle traduit les identifiants des tables ou de colonnes par des noms que nous lui avons affectés. Autre précision le logminer doit être installé pour être utilisable, cependant il peut être installé sur une instance et analyser une autre instance.
Vous noterez qu'un autre article spécifique à logminer est disponible : ICI
7-2. Installation du LOGMINER▲
7-2-a. Paramètres pré-requis▲
Le paramétre UTL_FILE_DIR doit être positionné pour ouvrir un accès en lecture/écriture à un répertoire.
Par exemple : utl_file_dir="c:\oracle\utl, c:\oracle\utl2".
Tous les exemples sont exécutés sous le compte SYS.
7-2-b. Création du fichier de dictionnaire▲
Lancez la procédure de création DBMS_LOGMNR_D.BUILD. Elle va interroger les tables du dictionnaire principal de la base courante et crée un fichier texte avec leur contenu; ce fichier est placé dans le répertoire spécifié dans l'appel de la procédure.
C:\> set ORACLE_SID=BD0
C:\> sqlplus "/ as sysdba"
SQL> execute dbms_logmnr_d.build ('dictionnary.ora', -
'c:\oracle\utl');
La mise en place d'un fichier de dictionnaire n'est pas obligatoire mais elle améliore grandement
la lisibilité des fichiers REDO et des informations que nous irons chercher dans la vue dynamique V$LOGMNR_CONTENTS,
et facilite donc de ce fait le travail du DBA. Plus précisément le fichier du dictionnaire est utilisé par le logminer
pour convertir chaque identifiant interne d'objet en nom de structure plus explicite, par exemple ce n'est pas l'object_id mais bien l'object_name
qui sera mentionné.
Quelques précautions sont à prendre lors de la création du fichier de dictionnaire. Tout d'abord veillez bien à ce que le fichier du dictionnaire soit
en rapport avec la date des fichiers REDO, à savoir si votre fichier date et qu'il ne recense pas des objets nouvellement crées, logminer ne sera pas
en mesure d'afficher le nom de l'objet ni de ses éventuelles colonnes. Un fichier de dictionnaire doit être créé dans la base à l'origine du journal
de reprise à analyser. Nous ne pouvons pas nous servir d'un fichier de la base BD0 pour analyser BD1.
7-2-c. Spécifier les fichiers LOG à analyser▲
Logminer analysera les fichiers REDO que nous allons lui indiquer, par conséquent, nous devons lui indiquer les fichiers à analyser grâce à la procédure DBMS_LOGMNR.ADD_LOGFILE
SQL> execute Dbms_logmnr.add_logfile ('c:\temp\BD0T001S00048.ARC', -
dbms_logmnr.new);
Procédure PL/SQL terminée avec succès.
L'option DBMS_LOGMNR.NEW permet de créer une nouvelle list de fichier, DBMS_LOGMNR.ADDFILE permet d'ajouter un fichier à cette liste et
DBMS_LOGMNR.REMOVEFILE permet de supprimer un fichier de la liste.
La vue V$LOGMNR_LOG permet de vérifier que le fichier a bien été pris en compte.
SQL> select db_name, thread_sqn, filename from v$logmnr_logs ;
DB_NAME THREAD_SQN FILENAME
---------- --------------- ----------------------------------------------
BD0 48 c:\temp\BD0T001S00048.ARCVous l'aurez compris, db_name, tread_sqn et filename représentent successivement, le nom de la base de données, le numéro de séquence du fichier et son chemin sur le disque.
7-2-d. Lancer l'analyse▲
SQL> Execute dbms_logmnr.start_logmnr(dictfilename='c:\oracle\utl\dictionary.ora') ;La procédure DBMS_LOGMNR.START_LOGMNR accepte différentes options, notamment un SCN de départ et/ou un SCN de fin pour délimiter le champ de l'analyse, ou une horodate de début et/ou de fin.
SQL> Execute dbms_logmnr.start_logmnr (dictfilename='c:\oracle\utl\dictionary.ora',
Startscn= 125,
End scn = 300);SQL> Execute dbms_logmnr.start_logmnr(
dictfilename='c:\oracle\utl\dictionary.ora',
Starttime = to_date('01-nov-2003 12:20:00',DD-MON-YYY HH:MI:SS'),
Endtime = to_date('06-nov-2003 12:00:00',DD-MON-YYY HH:MI:SS')
);Le contenu des fichiers est consultable dans la vue V$LOGNMR_CONTENTS.
7-2-e. La vue V$LOGNMR_CONTENTS▲
Les fichiers recensés dans V$LOGMNR_LOGS sont lus en séquence et les données sont retournées dans la structure définie par V$LOGMNR_CONTENTS. Cette vue se décompose en 53 colonnes. Voyons d'un peu plus prés quelles sont les colonnes les plus pertinentes :
| Colonne | Description |
|---|---|
| OPERATION | L'opération enregistré dans l'entré de reprise (insert, update, delete, ...). |
| TIMESTAMP | L'horodate à laquelle le changement de données s'est produit |
| SCN | Le numéro de changement système d'une modification |
| SEG_OWNER | Le nom du propriétaire du segment |
| SEG_NAME | Le nom du segment dans lequel le changement de données s'est produit |
| SEG_TYPE | Le type du segment ayant fait l'objet d'une modification |
| TABLE_SPACE | Le nom du tablespace auquel appartient le segment modifié |
| ROW_ID | L'identifiant interne de la ligne concerné par la modification |
| USER_NAME | L'utilisateur à l'origine de la modification |
| SESSION_INFO | Les informations de connexion de l'utilisateur au moment de la modification |
| SQL_REDO | L'instruction SQL qui reproduirait la modification spécifique à l'origine de cette entrée de reprise |
| SQL_UNDO | L'instruction SQL qui déferait la modification à l'origine de cette entrée de reprise |
Grâce à la colonne SQL_UNDO nous allons donc pouvoir annuler la modification d'une mise à jour, insertion, suppression ou toute autre opération portant sur un objet de la base de données.
Mais vous pouvez également, connaître quel utilisateur a effectué ces modifications ainsi que l'identifiant de la machine (sauf si l'opération a été effectuée par le biais d'une application tierce).
Autre tâche que peut effectuer pour vous le LOGMINER c'est celle d'auditer votre base de données ou vos objets. L'avantage par rapport à l'audit de base est le fait important que le LOGMINER, contrairement à l'audit,
n'ajoute pas un traitement de service susceptible de nuire aux performances.
Il existe une version graphique du LOGMINER à partir de la version 9i intégrée à OEM.
8. Annulation d'un ordre DML▲
Oracle 9i permet de positionner une session dans le passé pour restituer les blocs de données sauvegardés dans le UNDO.
Cette méthode est une excellente alternative à Logminer pour annuler une erreur de saisie par exemple.
Pour plus de détail sur le Flashback Query, vous pouvez lire ce tutoriel : Le FLASHBACK QUERY sous Oracle 9i.
9. Bibliographie▲
Ces documents sont tous issus de la documentation d'Oracle en ligne et nécessitent un enregistrement gratuit.
Backup and Recovery Concepts
Oracle Data Guard Concepts and Administration
Using LogMiner to Analyze Redo Logs (Chapitre 9 de Oracle9i Database Administrator's Guide)
Flashback Query (Chapitre 20 de Oracle9i Database Concepts)
Net Services Administrator's Guide
Remerciement▲
Je tiens à remercier toute l'équipe de Developpez.com pour son aide dans la relecture et l'amélioration du présent tutoriel. Un grand merci à Orafrance sans qui ce document n'aurai jamais pu voir le jour, merci à toi pour ta patience et ton expertise, qui ont rendu ce document meilleur. Merci également à Beuss pour la correction de l'orthographe.